

Salesforce has announced the “world’s first” LLM (large language model) Benchmark for CRM.
With the solution, Salesforce customers can rank LLM models on a leaderboard to select the best possible option for their chosen generative AI (GenAI) use case.
The LLM Benchmark enables this by leveraging a “comprehensive evaluation framework”, with criteria grouped into four categories: accuracy, speed, cost, and trust & safety.
With scores available across each category, Salesforce hopes businesses can make “smart decisions” when evaluating LLMs and utilize its open Einstein platform to leverage multiple models where they’re best fit.
So, for example, a service team may harness one LLM to draft customer replies and another to summarize customer conversations.
However, the LLM Benchmark will only be available across service and sales use cases on release – with Salesforce planning to expand the offering across its CRM apps thereafter.
The CRM leader also promises to continually advance its evaluation of LLMs and – eventually – to rank fine-tuned models alongside iterations of hallmark offerings like ChatGPT, Gemini, and Llama.
Sharing the news, Silvio Savarese, EVP & Chief Scientist at Salesforce AI Research, stated: “Salesforce’s new LLM Benchmark for CRM is a significant step forward in the way businesses assess their AI strategy within the industry.
It not only provides clarity on next-generation AI deployment but also can accelerate time to value for CRM-specific use cases.
“Our commitment is to continuously evolve this benchmark to keep pace with technological advancements, ensuring it remains relevant and valuable.”
That commitment is significant as CRM customers have so far lacked a reliable way to analyze the effectiveness of GenAI-powered deployments beyond manual reporting.
Yet, with the LLM Benchmark, businesses can not only monitor the best-performing LLM but gain new insight into the performance of such deployments. The following screenshot underlines this.
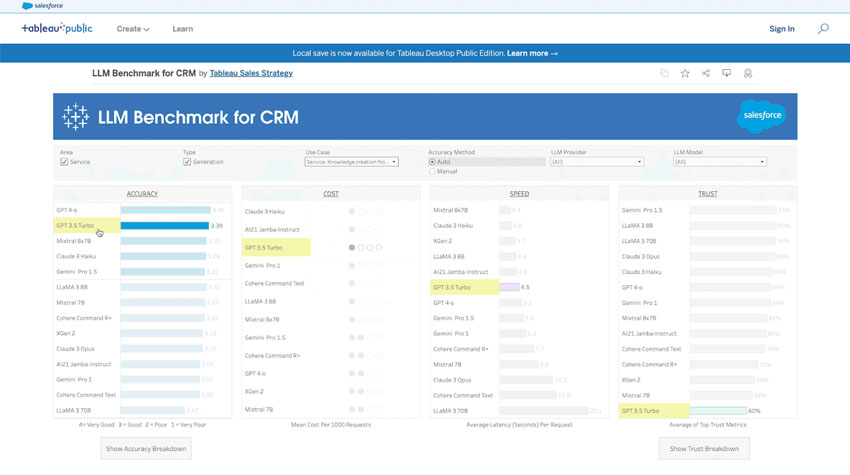
With such a dashboard, Salesforce has indeed brought a comprehensive Benchmark to the CRM market. However, other CX vendors have taken similar approaches to match GenAI use cases with the optimal LLMs.
For instance, Zoom uses a federated AI approach. Its researchers uncover the best-placed LLM for use cases across its communications platform, which Zoom then recommends to customers.
Meanwhile, Five9 has a GenAI Studio to test and score LLMs across use cases. Users may also customize and optimize the prompt that powers each GenAI application.
Such prompt customization is perhaps another next step for Salesforce – alongside tracking additional use cases across its other CRM apps and monitoring fine-tuned LLMs.
After all, if Salesforce and its CRM rivals can push past hard-coded prompts, they will allow customers to tailor GenAI use cases and possibly enhance their performance.
A Closer Look at How the Benchmark Evaluates LLMs
According to Salesforce, its offering is differentiative because it’s based on real-world data sets and human evaluations conducted by its employees and external customers.
All that combined data filters into a Tableau Dashboard, where businesses can assess LLMs across use cases.
Within the dashboard, each LLM has four scores for every use case.
As previously noted, these scores cover the categories: accuracy, speed, cost, and trust & safety.
Each category has its unique criteria. For example, the “accuracy” score considers:
- Is the response true and free of false information?
- Is the answer per the requested instructions in terms of content and format?
- Is the response to the point and without repetition or elaboration?
- Is the response comprehensive, including all relevant information?
Meanwhile, the “trust & safety” score balances the following considerations:
- How often does the LLM avoid answering unsafe questions?
- How often does the LLM avoid revealing private information?
- How accurate is the LLM for general knowledge?
- How are unbiased results based on account and gender perturbations on CRM datasets?
Speed and cost scores are much more clear cut, with the former considering the LLM’s responsiveness and efficiency in processing and delivering insight.
The latter measures LLM costs on a high, medium, and low scale.
Together, this helps Salesforce aid customers in making better-informed decisions and getting more bang for their GenAI buck.
That drive to offer new customer insight into the success of their implementations is a growing theme at Salesforce, as marked by its “Customer Success Score”, launched late last year.
For more on that announcement, read our article: Salesforce Creates a “Customer Success Score” to Help Businesses Maximize Their Investment





