

CX Observability is emerging as a critical discipline for modern contact centers. Unlike traditional monitoring, which tracks system health in isolation, CX observability connects customer experience signals across applications, networks, agents, and infrastructure to explain why interactions fail – not just when they fail.
When customer conversations slow down, break, or disappear entirely, the contact center becomes the loudest problem in the business. Not because it failed first, but because it is where failure becomes visible…and expensive.
That is why CX Today sees ‘CX Observability’ as increasingly essential.
Navigation Guide:
Defining CX Observability
Why CX Observability is Crucial in the Contact Center
Understanding the Vendor Market Map
CX Observability: Adoption & Success
What Is CX Observability? (The CX Today Definition)
CX observability is the practice of collecting, correlating, and acting on technical, operational, and experience signals across the contact center stack. This helps contact center leaders to understand what customers and agents are experiencing in real time.
CX observability is not yet a fully standardized category in the way CCaaS or WEM (Workforce Engagement Management) are. Different vendors describe the same buyer problem using different language, including contact center monitoring, CX assurance, voice quality monitoring, digital experience monitoring, and full-stack observability.
So what makes CX observability distinct?
It goes beyond traditional contact center reporting by connecting signals from across the stack, such as:
- Technical telemetry from applications and infrastructure, often described as MELT (Metrics, Events, Logs, Traces)
- Agent environment conditions, like device performance and browser behavior
- Network and voice quality signals, like latency, jitter, and packet loss
- WebRTC (Web Real-Time Communications) media performance for browser-based voice and video
- Customer journey and interaction context, including handoffs and drop-offs
- Proactive CX assurance through synthetic or controlled journey testing
- Operational context, including what changed and who owns the response
Here’s CX Today’s definition: CX observability is how you turn “something feels off” into evidence, ownership, and action.
Read More
CX Observability vs QA, WEM, and APM
This is where many definition pages fall short. They describe one tool, then relabel it as “observability.” In reality, these categories overlap, but they are not the same thing.
QA (Quality Assurance)
QA focuses on evaluating interactions for coaching, compliance, and performance insight. It is essential for improving customer conversations. It is not designed to diagnose cross-stack performance degradation in real time.
WEM
WEM focuses on workforce performance and enablement, such as coaching, scheduling, and performance management. These tools can provide useful operational signals. They are not end-to-end diagnostic layers across the contact center stack.
APM (Application Performance Monitoring)
APM focuses on application health and performance, often using code-level traces and dependency mapping. These tools can be powerful foundations for observability programs. They can also miss the last mile, including agent hardware conditions, ISP (Internet Service Provider) latency, and voice quality degradation.
CX observability is a discipline that often pulls from several of these factors.
CX Observability vs Service Management
These two pathways solve different parts of the same reliability problem. CX observability helps you understand what is happening across the contact center stack, and why the experience is degrading. Service management is how your organization responds once that degradation is detected, including ownership, escalation, communication, and follow-up.
A simple way to separate them is this: CX observability turns “something feels off” into evidence. Service management turns evidence into action. Without observability, service management teams can end up running well-organized guesswork. Without service management, observability can become a stream of alerts with no consistent resolution path.
CX Observability vs Digital Experience Monitoring (DEM)
Digital Experience Monitoring (DEM) focuses on how digital channels perform from the user’s point of view. It commonly uses RUM (Real User Monitoring) and synthetic testing to measure things like page load time, errors, crashes, and journey drop-offs. DEM is especially strong for web and mobile experiences where friction is visible in clicks, taps, and page behavior.
CX observability overlaps with DEM, but it is broader in contact center environments because it needs to account for voice and real-time interactions, agent desktops, WebRTC media performance, network paths, and system dependencies like CRM and identity services.
Here is CX Today’s take: DEM often explains why a customer struggled in a digital journey. Meanwhile, CX observability explains why that struggle may also be affecting assisted service, like voice calls, chat escalations, or agent productivity.
CX Observability vs CX Assurance
CX assurance is proactive validation of customer journeys through automated testing. It often uses synthetic interactions such as test calls, interactive voice response (IVR) simulations, chatbot tests, or scripted digital journeys to confirm that experiences work as expected. The goal is to catch failures early, ideally before customers notice.
CX observability is the broader discipline of collecting and correlating signals across customer experience, agent experience, applications, infrastructure, and network paths to diagnose why performance is degrading in real time.
If you’re still confused, we recommend thinking about it this way: Assurance answers “does the journey work?” Observability answers “what is degrading, where is it happening, and why?”
Why Is CX Observability Rising in Modern Contact Centers?
CX observability is rising because the contact center is no longer one system. It is an operating environment built on a chain of dependencies.
Cloud architectures increased the dependency chain
Modern CX environments commonly depend on CCaaS, CRM, identity services, integration pipelines, and cloud infrastructure. When those dependencies are distributed, traditional monitoring can struggle to explain why the experience is degrading.
Remote and hybrid agents expanded the “last mile”
A contact center can be stable in the cloud and still feel broken to an agent. Wi-Fi congestion, headset issues, browser versions, CPU spikes, and local internet instability can degrade calls and digital channels. These conditions can be invisible in platform-only dashboards.
This is one reason voice quality monitoring is now discussed alongside CX observability. Many “CX issues” are last-mile issues.
AI created new failure modes that can scale quickly
AI can improve routing, automation, and agent productivity. It also introduces new failure patterns. Model behavior can drift. Automated workflows can fail silently. Context can get lost during a handoff between a voice bot and a human agent.
What Are the Core Capabilities of A CX Observability Platform?
A useful capability framework maps to outcomes, not feature lists.
Monitoring
Real-time visibility into performance and experience indicators across CX and technical layers.
Correlation
The ability to connect customer, agent, application, and network signals into one story of cause and effect. Correlation is where monitoring becomes observability.
Assurance and testing
Synthetic or controlled testing that catches issues before customers complain, then validates whether fixes actually worked.
Root-cause analysis
Workflows and tooling that help teams identify where failures originate and reduce duplicated investigation across teams.
Alerting and remediation
Insight needs to connect to action. Alerting must be tuned to avoid noise. Remediation needs to connect to ownership and workflows, otherwise observability becomes “interesting” but not useful.
Optimization
Using observability signals to improve reliability, customer experience, agent experience, and cost efficiency over time.
What Are the Business Benefits of CX Observability?
CX observability wins investment through outcomes leaders recognize.
Faster diagnosis and fewer blame loops
When signals are siloed, teams argue. When signals are correlated, teams diagnose. CX observability reduces duplicated investigation across CX operations, IT operations, network teams, and vendors.
Less customer-visible disruption
The goal is not only to fix issues faster. The goal is to detect issues earlier and shrink the blast radius. That is where proactive assurance and strong correlation pay off.
Better agent productivity
Agents lose time when calls degrade, desktops slow down, and workflows break. CX observability helps teams identify whether the bottleneck is voice quality, internet path behavior, CRM latency, identity failures, or local device conditions.
Smarter investment decisions
Observability helps organizations stop guessing. It can reveal which integrations are fragile, which workflows degrade under load, and where reliability investment will pay off.
Which Vendors Are Shaping the CX Observability Market?
CX observability is easier to understand when you think in approaches, not “winners.” Different vendors solve similar reliability problems from different starting points.
Many enterprises blend multiple approaches, especially during cloud migrations and modernization cycles.
To make it easier for prospective buyers, here is CX Today’s framework for understanding CX observability vendors and what they’re best suited for:
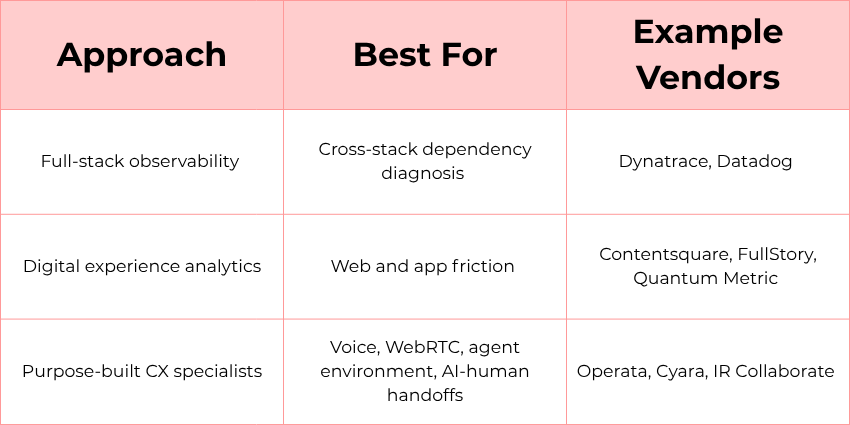
Full-stack observability platforms
These platforms provide broad telemetry and correlation across enterprise applications, infrastructure, and services. They tend to be most valuable when the “CX issue” is actually a dependency issue, such as CRM latency, identity timeouts, API degradation, or cloud region instability.
Examples include:
- Dynatrace: Known for “Davis AI,” which supports causal, deterministic root cause analysis, and for automated dependency discovery and topology mapping that reduces manual effort in complex environments.
- Datadog: Often chosen for modularity and a wide integration ecosystem, with flexible dashboards, but typically requiring more manual configuration for dependency mapping and offering many separately licensed modules that can complicate cost forecasting.
Digital experience analytics specialists
These tools focus on the “front end” of experience, capturing how users interact with websites and mobile applications. They help teams see friction patterns such as errors, dead ends, and “rage clicks,” and connect that friction to business impact.
Examples include:
- Contentsquare: Strong on “impact quantification,” tying user experience issues to revenue impact to help teams prioritize fixes, with a visual interface designed for business and product teams.
- FullStory: Known for high-fidelity session capture that can retroactively replay user interactions, with “privacy by default” features such as masking to reduce sensitive-data exposure.
- Quantum Metric: Built for very large scale, with tooling designed to surface and summarize friction and connect it to business impact in real time.
Purpose-built CX specialists
These vendors focus on contact center-specific visibility gaps that general-purpose tools often miss, such as real-time media quality, agent environment conditions, and handoffs between AI and humans.
Examples include:
- Operata: Positions itself as “Datadog for contact centers,” with a focus on contact-center-specific telemetry and correlation. This includes the ability to trace journeys across Voice AI (voice artificial intelligence), CCaaS, and human handoffs into a single timeline.
- Cyara: Known as a CX assurance leader, combining proactive testing with monitoring, including voice quality metrics such as MOS (Mean Opinion Score) and agent workstation health signals at scale across many geographies.
- IR Collaborate: Built on the Prognosis platform, supporting multi-vendor unified communications and contact center environments, including natural language querying through its “Iris” AI layer.
Disclaimer: This is a sample of the market, not a complete list of vendors. If you’re a vendor in this space and would like to be considered for inclusion in future updates, please get in touch.
What Should Buyers Look for in a CX Observability Vendor?
CX observability purchasing goes wrong in one predictable way. Buyers evaluate dashboards. They do not evaluate diagnosability.
Start with what the platform can actually see, then pressure-test how it turns visibility into diagnosis and action.
Coverage across the contact center stack
Ask what signals the platform can capture across voice quality monitoring, WebRTC media, agent environments, network paths, CCaaS performance, CRM dependencies, identity services, integration pipelines, and AI workflows.
Correlation that leads to diagnosis
Dashboards are not enough. Ask how the platform links customer symptoms to technical causes. Ask how it reduces time from “we saw it” to “we know where it is.”
Proactive assurance options
If CX assurance is a priority, treat it as a requirement. Ask how testing is implemented, how often it runs, and how results connect to alerting and incident workflows.
Noise control and alert quality
Ask what “good” looks like after 30 days. Many tools fail because they create noise, not insight.
Workflow integration into incident response
Observability should connect to incident response and service management workflows. Detection without routing still wastes time.
Governance and privacy clarity
If agent environment signals are involved, ask how data is handled, masked, accessed, and retained. The goal is reliability signals, not surveillance.
How Do You Implement CX Observability Across the Buyer Journey?
Organizations get better results when they match the approach to maturity. Here is CX Today’s guide for every step of your journey:
Discovery stage
Define the problem in operational language. “CX is unreliable” is not a requirement. “Transfers fail during peak hours for customers in region X” is a requirement.
Consideration stage
Identify the biggest visibility gap. Is it correlation, last-mile voice quality monitoring, proactive CX assurance, or workflow integration?
Evaluation stage
Test real scenarios. Use one recurring incident you already know and one degradation pattern that triggers customer complaints. Require vendors to show how they connect symptoms to causes across the stack.
Post-purchase stage
Implement in phases so the tool becomes an operating capability, not shelfware.
A practical 90-day pattern:
- Days 1–30: connect signals, tune alerting, align routing, close telemetry gaps
- Days 31–60: build playbooks, validate assurance tests, reduce repeat incidents
- Days 61–90: report results in business terms, expand coverage, operationalize learning
How Do You Measure and Prove ROI for CX Observability?
CX observability is often undervalued because reliability improvements can feel like “avoided pain,” which is harder to quantify than new revenue.
We recommend the simplest approach: Track a small set of operational indicators, then connect them to customer outcomes.
Start with operational performance:
- Time to detect
- Time to diagnose
- Time to restore
- Reduction in repeat incidents
Then connect those improvements to CX outcomes:
- Fewer abandoned interactions
- Fewer repeat contacts and escalations
- More efficient use of agent time
- More predictable service delivery
Executives do not need complex models. They need clear evidence that reliability improvements translate into fewer customer-visible failures and smoother operations.
This is also where downtime benchmarks can help justify investment. Research shows that downtime can exceed $300,000 per hour in many enterprises. Therefore, reducing the frequency, duration, and blast radius of IT issues can be a material ROI story.
If you need another way to translate observability wins into executive language, read How to Prove CX Service Management ROI.
Final Thoughts: Is CX Observability a Real Category or a Useful Label?
Right now, it is both.
It is an emerging label and not yet standardized like CCaaS or WEM. Many vendors still frame the buyer problem through adjacent categories.
It is also a useful label because it describes a real operational need: correlating technical telemetry with experience outcomes across customer, agent, platform, and network layers.
The most practical way to treat CX observability is as a discipline:
- It reduces uncertainty and speeds diagnosis.
- It makes degradation visible, not just outages.
- It supports safer AI operations by making automated workflows observable.
To connect CX observability to the broader reliability operating model, read CX Service Management: The Ultimate Guide.
FAQs
What is CX observability?
CX observability is the practice of collecting and correlating technical, operational, and experience signals across the contact center stack to understand what customers and agents are experiencing in real time.
What is the difference between contact center monitoring and contact center observability?
Contact center monitoring is often platform-centric and threshold-based. Contact center observability focuses on correlation across customer, agent, application, and network signals to explain why performance is degrading.
What is CX assurance and how does it relate to CX observability?
CX assurance is proactive validation of customer journeys through synthetic or controlled testing. It complements CX observability by catching issues early and confirming whether fixes worked.
Why is voice quality monitoring important for CX observability?
Voice quality monitoring tracks signals like latency, jitter, packet loss, and MOS that directly affect call clarity. These signals often explain “the platform looks fine, but calls are bad” scenarios, especially for remote and hybrid agents.
How do I start implementing CX observability without creating tool sprawl?
Start with one high-impact use case, connect the signals you already have, tune alerts to reduce noise, and integrate observability into incident workflows. Prove one measurable improvement in the first 90 days, then expand.





